白日惊雷
“你的python应用cpu占用快90%了!!!”,良哥朝我眨了眨布满血丝的眼睛
“不会吧”,我心想:我这是好的啊
没接触过kafka的同学可以先了解下:(http://www.jasongj.com/2015/03/10/KafkaColumn1/)
疑云重重
SSH到远程机器上,运行top命令看一下,果然平常4%不到的cpu占用,现在飙升到90%左右了。
这是一个简单的应用:server端从kafka读消息,通过websocket发送到client端,整个server端代码也就几百行。
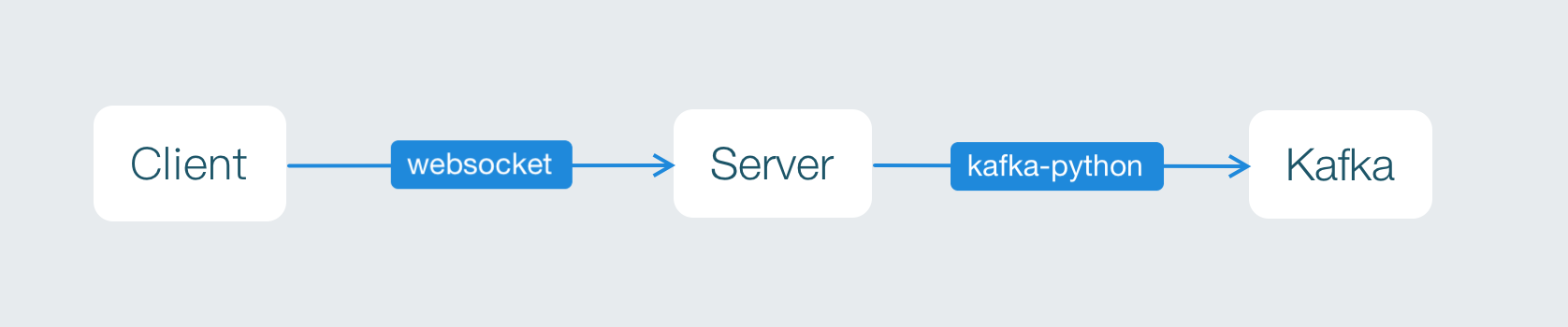
那就直接看代码吧。
由于线上环境的kafka没有开放端口,我是在本地搭的kafka环境,所以为了快速开发,就在server端直接写了一个kafka生产者,向kafka提交消息。因此,
猜想1: 难道是不小心把kafka生产者的代码也提交上去了?
check最新代码,生产者的代码明显被注释掉了,并没生效。
猜想2:websocket与server端链接太多了?
不可能,这个功能目前还没开始公测,而且只有这一个server cpu占比过高。
那还是server和kafka之间出现了问题。
初现端倪
server端会在每个请求到来时创建一个websocket连接,同时创建一个kafka消费者线程,用来监听特定topic的消息。
client端与server端的websocket会在用户刷新页面或者关闭页面时断开连接,这个不会有问题。那问题有可能出在:创建的kafka消费者线程没有正确地退出。
每个python线程会有一个daemon属性,默认为False。python主线程会在所有daemon为False的线程退出后才终止,而daemon为True的线程(也就是后台线程)会在主线程退出时一起退出。
所以无论如何,每次发布时都是重启整个进程,不会有资源回收失败的问题。
那就是在server运行时创建了过多的kafka消费者线程。
验证一下,打开pycharm的并发状态检测开关并启动server,新开一个页面,连续刷新几次,pycharm里就可以看到刚才创建的线程活的好好的!!!
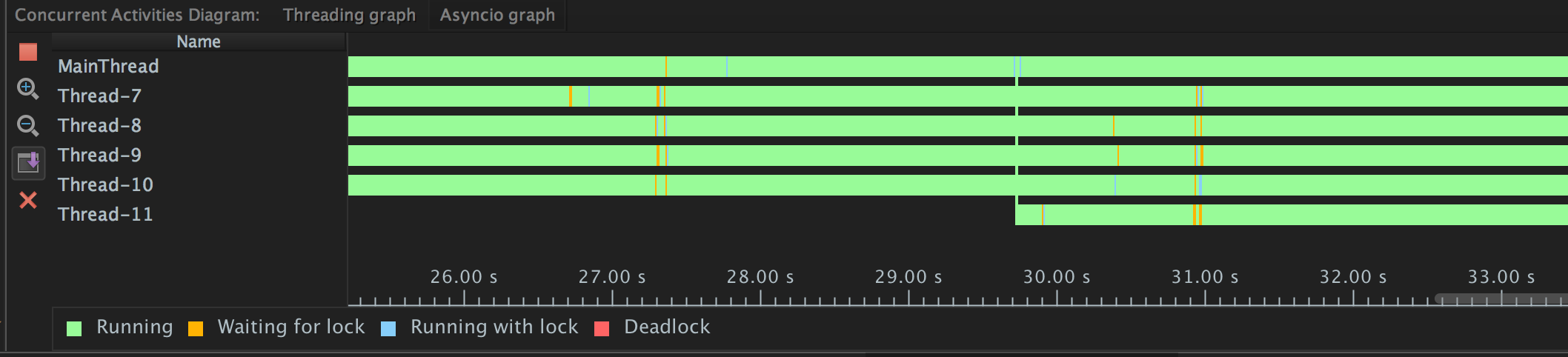

水落石出
那来看看kafka消费者线程在干什么。
kafka消费者线程负责:
连接kafka
获取消息
向websocket连接写入消息
祭出debug神器:断点
根据多年打断点的经验,果断滴选择了“获取消息”。
经过一段时间的调试,原来是kafka-python从kafka获取消息时会进入无限while循环,从而阻塞线程。
解决方案
既然弄明白了问题的来龙去脉,解决起来就容易了。
首先看kaka-python有没有异步api,在官方文档里找了一圈,并没有,最后发现

,利用异常我们可以跳出while循环,从而有机会结束当前线程。大致代码如下:
class ConsumerThread(Threading.thread):
...
def fetchMsg(self):
for message in self.consumer:
if self.stopThread:
break
message_value = message.value
socket.pubsub(message_value)
else:
logger.error('consumer timeout')
if not self.stopThread:
self.fetchMsg()
else:
self.consumer.close()
一些感想
连接kafka的kafka-python竟然没做成事件驱动,反而是阻塞式,这不明显是挖坑让人跳么?

